File I/O
Most sufficiently complex applications need to persist data. While databases are often used to persist complex hierarchical data, less complex data can be written to a text or binary file. In this module we’ll explore the use of file streams for reading and writing files.
Table of Contents
- Objectives
- Reading and Writing Files
- File Streams
- Opening File Streams
- Check If Files Open Successfully
- Closing Files
- Writing To A Text File
- Reading From a Text File
- Reading a Line of Text at a Time
- Reading Basic Delimited Text Data
- Simpler Delimited Text Data with Spaces
- Reading Structured Text Data
- Binary File Access
- Streaming Binary Structures
- Vector Iterator Trick with Binary Data
- Random File Access
- Random Access Example
- Struct Padding and Binary Files
- Filesystem Library
- Further Reading
Objectives
Upon completion of this module, you should be able to:
- Open files for reading and writing using file streams.
- Create file streams for text and binary data.
- Write data to a text file using basic delimiter strategies.
- Use overloaded stream operators to read and write data to a text file.
- Read and write binary data sequentially and through random access.
Reading and Writing Files
Questions you’ll want to ask when reading and writing data to a file:
- Should the data be stored in a human-readable text format, or a binary format that will be much harder for a human to verify? (This decision may come down to speed or file-size requirements.)
- If a human-readable text format is desired, are you going to create your own custom format or use an established text format like CSV or JSON? (Except for the simplest data, an established format is preferred.)
- If you’re storing binary data in text form, what encoding format will you use? (Ex. Base64)
- If you’re storing binary data, do you need to read data written by machines with different binary endianness?
In the examples below we’ll explore simple text and binary storage without using established formats or worrying about endianness.
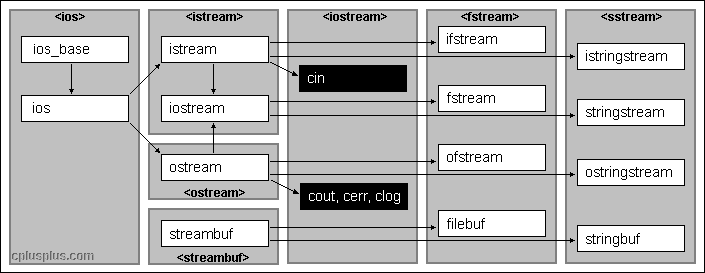
File Streams
File I/O is based on the stream-base I/O we learned about in the console I/O section.
Let’s start by reviewing the stream hierarchy:
🎵 Note:
The fstream header is required to use the ifstream, fstream, and ofstream classes.
Opening File Streams
Unlike cout and cin which are available for streaming by default, we need to open files before we can stream to/from them.
#include <fstream>
int main() {
std::fstream inOutFile{"in-out-filename.txt"}; // Default Mode: ios_base::in | ios_base::out
std::ofstream outputFile{"output-filename.txt"}; // Default Mode: ios_base::out | ios_base::trunc
std::ofstream appendFile{"append-filename.txt", std::ios_base::app}; // Append output, don't truncate file.
std::ifstream inputFile{"input-filename.txt"}; // Default Mode: ios_base::in
}
Check If Files Open Successfully
File streams can be tested as booleans to see if the file opened successfully:
#include <fstream>
#include <iostream>
int main() {
std::ofstream outputFile{"output-filename.txt"};
if (!outputFile) {
std::cerr << "Could not open output file.\n";
}
std::ifstream inputFile{"input-filename.txt"};
if (!inputFile) {
std::cerr << "Could not open input file.\n";
}
}
Closing Files
Files opened for input or output are automatically closed when their associated variable goes out of scope. They can also be manually closed earlier than this using the .close() method.
#include <fstream>
int main() {
std::ofstream outputFile{"output-filename.txt"};
// Nah, changed my mind:
outputFile.close();
}
Writing To A Text File
To write to a file we use the insertion operator: <<
#include <iostream>
#include <fstream>
#include <string>
int main() {
std::ofstream outputFile{"output.txt"};
int flightlessBirdCount = 12;
double portionOfPotion = 56.2;
std::string confusion = "That wasn't what I meant when I said 'Yes'.\n";
outputFile << "First line of output.\n";
outputFile << "Second line of output.\n";
outputFile << confusion;
outputFile << flightlessBirdCount << " " << portionOfPotion << "\n";
}
Reading From a Text File
To read from a file we can use the extraction operator >> along with the fact that the stream itself will return 0 (which evaluates to false in C++) if we’ve reached the end of the file (EOF).
#include <iostream>
#include <fstream>
#include <string>
int main() {
std::ifstream inputFile{"input.txt"};
while (inputFile) { // 0 (false) when EOF
std::string data;
inputFile >> data; // Read until space character or end of line.
std::cout << data << "\n";
}
}
Assuming an input.txt structured like this:
First line of output.
Second line of output.
That wasn't what I meant when I said 'Yes'.
12 56.2
🎵 Note:
The >> uses the space and end-of-line characters as delimiters.
Reading a Line of Text at a Time
We can use std::getline() to read one line at a time from an input stream. The newline character is not included in the read data.
#include <iostream>
#include <fstream>
#include <string>
int main() {
std::ifstream inputFile{"input.txt"};
while (inputFile) {
std::string data;
std::getline(inputFile, data);
std::cout << data << "\n";
}
}
Reading Basic Delimited Text Data
When storing numbers to a file we need some way to keep numbers from getting combined. You don’t want to write a 40 beside a 22 and have that read back in as 4022.
Imagine a simplified version of the CSV format that is simply comma-delimited integers:
#include <fstream>
#include <iostream>
int main() {
std::ifstream inputFile{"delimited-input.txt"};
int number;
while (!inputFile.eof()) {
if (inputFile >> number) {
std::cout << number << "\n";
} else {
// If reading a number failed, we've hit a delimiter.
inputFile.clear(); // Clear the fail bit.
// Read in the delimiter character and ensure it's a comma.
if (char delim; inputFile >> delim) {
if (delim != ',') {
std::cerr << "Whoops, bad character: " << delim << "\n";
}
}
}
}
}
Try it with a delimted-input.txt like this:
1,2,3,4,5,6,7,8,9,10,11,12
900,800,700,600,500.400,$300wat200
🎵 Note:
Using a C++17 “if initializer” on line 13.
Simpler Delimited Text Data with Spaces
Reading delimited data is simplified with a space character delimiter, as the input stream will automatically consume the spaces.
#include <iostream>
#include <fstream>
int main() {
std::ifstream inputFile{"simpler-input.txt"};
int number;
while (inputFile >> number) { // Stops if we come across bad data.
std::cout << number << "\n";
}
}
Try it with a simpler-input.txt like this:
1 2 3 4 5 6 7 8 9 10 11 12
900 800 700 600 500 400 300a 200
Reading Structured Text Data
Recall in our section on operator overloading we created a Money class with custom i/o stream operators.
With an overloaded << operator for input streams we can easily read well-formatted files into vectors:
// Open input stream:
std::ifstream inputFile{"input-file.txt"};
// Read all Money entries from the file into a vector:
std::vector<Money> bank{ // Constructor the vector using an iterator:
std::istream_iterator<Money>{inputFile},
{} // Short form for the end of the iterator.
};
// Loop through the received Money entries:
for(Money money : bank) {
std::cout << money << "\n";
}
Here’s a version of the Money class used to read in a file of dollar amounts, one per line, in the $m.n format (where m and n are integers):
#include <fstream>
#include <iostream>
#include <iterator>
#include <string>
#include <vector>
class Money {
static constexpr int centsPerDollar{ 100 };
int mDollars{ 0 };
int mCents{ 0 };
// Ensure that we never have more than 99 cents.
void rollCentsIntoDollars() {
int additionalDollars{ mCents / Money::centsPerDollar };
mDollars += additionalDollars;
mCents %= Money::centsPerDollar;
}
public:
Money(int dollars, int cents) : mDollars{dollars}, mCents{cents} {
rollCentsIntoDollars();
}
Money() = default; // Required for line 59 (no-arg initialization).
// Overloaded stream output (friend)
friend std::ostream &operator<<(std::ostream &out, const Money &money) {
std::string padding{money.mCents < 10 ? "0" : ""};
out << "$" << money.mDollars << "." << padding << money.mCents;
return out;
}
// Overloaded stream input (friend). Note the out vars.
friend std::istream &operator>>(std::istream &in, Money &money) {
int dollars, cents;
char dollarSign, dot;
// Parses input in the form: $m.n (where m and n are integers)
in >> dollarSign >> dollars >> dot >> cents;
if ((dollarSign != '$') || (dot != '.')) {
in.setstate(std::ios_base::failbit); // Mark input as failed.
} else {
money = Money{dollars, cents};
}
return in;
}
};
int main() {
// In this example we'll read this file in two ways.
// Money values in this file can be space *and* new-line delimited.
std::ifstream inputFile{"money-input.txt"};
// Read Method 1: Manually "babysit" the import:
std::cout << "Manually reading entry by entry: \n";
while (!inputFile.eof()) {
Money money;
inputFile >> money;
if (inputFile.fail()) { // Test for the fail bit.
std::cerr << "Read bad money value.\n\n";
break;
} else {
std::cout << money << "\n";
}
}
// Some "house cleaning" between read examples:
// Clear the fail bit if above import read bad value.
inputFile.clear();
// Reset the file read pointer to the beginning of file.
inputFile.seekg(0, std::ios::beg);
// Read Method 2: Read all money at once using iterator:
std::cout << "Bulk reading using an interator: \n";
std::vector<Money> bank{std::istream_iterator<Money>{inputFile}, {}};
for (Money money : bank) {
std::cout << money << "\n";
}
}
Try it with a money-input.txt like this:
$42.12
$943.00 $555.55
$345.99
$56.25
wat
$0.12
🎵 Note:
For simplicity sake we’re halting all file parsing if we encounter a badly formatted entry.
Binary File Access
So far we’ve been reading and writing our data in text format. We can conserve space and potentially save time by writing in a binary format.
Let’s start by writing strings to a binary file. We will also need to store the length of each stored string so that they can be read back in separately.
include <iostream>
#include <fstream>
#include <string>
void writeString(std::string string, std::ofstream& out) {
size_t lengthOfString = string.length();
// First write the length of the string:
out.write(reinterpret_cast<char*>(&lengthOfString), sizeof(size_t));
// Then write the entire string in one go:
out.write(string.c_str(), sizeof(char) * lengthOfString);
}
std::string readString(std::ifstream& in) {
size_t lengthOfString;
std::string inputString;
// First read in the length of the string:
in.read(reinterpret_cast<char*>(&lengthOfString), sizeof(size_t));
// Resize storage for the received string:
inputString.resize(lengthOfString);
// Read in the string itself using the length:
in.read(&inputString[0], sizeof(char) * lengthOfString);
return inputString;
}
int main() {
std::ofstream outputFile{"output-input.bin", std::ios_base::binary};
std::string outputString;
// Write two strings to our binary file.
std::cout << "Please provide a string to write to the file: ";
getline(std::cin, outputString);
writeString(outputString, outputFile);
writeString("This is a hardcoded string.", outputFile);
outputFile.close();
// Read two strings from our binary file.
std::ifstream inputFile{"data.bin", std::ios_base::binary};
std::cout << readString(inputFile) << "\n";
std::cout << readString(inputFile) << "\n";
}
🎵 Note:
If we were actually just saving strings to a file we may as well be using a text file.
⏳ Wait For It:
Note the use of pointers, which we’ll cover in more detail in future sections.
Streaming Binary Structures
We can also write POD (Plain Old Data) structs to a binary file, as in structs that only contain primitives or other POD structs. This process is often called serialization or marshalling.
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
// Our POD:
struct PlainOldMoney {
int dollars;
int cents;
};
void writeVectorOfMoney(std::vector<PlainOldMoney> bank, std::ofstream& out) {
size_t lengthOfVector{bank.size()};
// First write the lenght of the vector:
out.write(reinterpret_cast<char*>(&lengthOfVector), sizeof(lengthOfVector));
// Then write the entire vector in one go:
out.write(reinterpret_cast<char*>(&bank[0]), sizeof(PlainOldMoney) * lengthOfVector);
}
std::vector<PlainOldMoney> readVectorOfMoney(std::ifstream& in) {
size_t lengthOfVector;
// First read back the length of the vector:
in.read(reinterpret_cast<char *>(&lengthOfVector), sizeof(size_t));
// Create a vector<PlainOldMoney> of the correct length:
std::vector<PlainOldMoney> inputVector(lengthOfVector);
// And then read back the vector of PlainOldMoney:
in.read(reinterpret_cast<char *>(&inputVector[0]), lengthOfVector * sizeof(PlainOldMoney));
return inputVector;
}
int main() {
// Sample vector<PlainOldMoney> to write to a file:
std::vector<PlainOldMoney> bank{
PlainOldMoney{5, 25}, PlainOldMoney{100, 00}, PlainOldMoney{0, 0}
};
// Write the vector to a binary file.
std::ofstream outputFile{"money-output-input.bin", std::ios_base::binary};
writeVectorOfMoney(bank, outputFile);
outputFile.close();
// Read the vector back from the binary file.
std::ifstream inputFile{"money-output-input.bin", std::ios_base::binary};
std::vector<PlainOldMoney> inputBank{readVectorOfMoney(inputFile)};
// Output the retrieved dollar amounts;
for(const PlainOldMoney &m : inputBank) {
std::cout << "$" << m.dollars << "." << m.cents << "\n";
}
}
🎵 Note:
For more on PODs see this StackOverflow response.
Vector Iterator Trick with Binary Data
Earlier we used an iterator to quickly fill a vector with input stream text data (parsed by an overloaded <<). We can use a similar trick to read in all a file full of binary data, if all we want are the raw bytes.
std::ifstream inputFile("input.bin", std::ios::binary);
std::vector<std::byte> data{
std::istreambuf_iterator<std::byte>(inputFile), // istreambuf iterator for binary data.
{}
};
Random File Access
So far with both our text and our binary files we’ve been writing and reading our data sequentially from the start of a file until the end. We can also perform what is called “random file access”, not as in accessing random locations, but as in the ability to read/write to/from arbitrary locations within a file.
- With input streams we can move the internal read pointer within the file using:
if.seekg() - With output streams we can move the internal write pointer within the file using:
of.seekp()
Movement performed with these functions is done relative to:
- The beginning of the file:
std::ios::beg - The current location within the file:
std::ios::cur - The end of the file:
std::ios::end
Assuming an ifstream named if:
if.seekg(0, std::ios::end); // move to end of file
if.seekg(0, std::ios::beg); // move to beginning of file
if.seekg(50, std::ios::beg); // Move to the 50th byte in the file.
if.seekg(50, std::ios::cur); // Move forward 50 bytes from the current position to the 100th byte.
🎵 Note:
The g in seekg stands for “get” and the p in seekp stands for “put”.
Random Access Example
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
// Our POD:
struct Money {
int dollars;
int cents;
};
void writeVectorOfMoney(std::vector<Money> bank, std::ofstream& out) {
size_t lengthOfVector{bank.size()};
// First write the length of the vector:
out.write(reinterpret_cast<char*>(&lengthOfVector),
sizeof(lengthOfVector));
// Then write the entire vector in one go:
out.write(reinterpret_cast<char*>(&bank[0]),
sizeof(Money) * lengthOfVector);
}
size_t readVectorLength(std::ifstream& in) {
// Ensure we are at the start of the file.
in.seekg(0, std::ios::beg);
size_t lengthOfVector;
in.read(reinterpret_cast<char *>(&lengthOfVector), sizeof(size_t));
return lengthOfVector;
}
Money readNthMoneyRecord(std::ifstream& in, size_t position) {
// Skip the size of the written vector length.
in.seekg(sizeof(size_t), std::ios::beg);
// Seek to the requested record.
in.seekg(sizeof(Money) * (position - 1), std::ios::cur);
Money m;
// Read the requested record.
in.read(reinterpret_cast<char *>(&m), sizeof(Money));
return m;
}
int main() {
// Sample vector<Money> to write to a file:
std::vector bank{Money{5, 25}, Money{100, 00}, Money{0, 0}};
// Write the vector to a binary file.
std::ofstream outputFile{"money-random-access.bin", std::ios_base::binary};
writeVectorOfMoney(bank, outputFile);
outputFile.close();
// Read the vector back from the binary file.
std::ifstream inputFile{"money-random-access.bin", std::ios_base::binary};
size_t numberOfRecords = readVectorLength(inputFile);
size_t recordToLoad;
std::cout << "There are " << numberOfRecords << " Money records.\n";
std::cout << "Which record do you wish to load: ";
std::cin >> recordToLoad;
Money money = readNthMoneyRecord(inputFile, recordToLoad);
std::cout << "$" << money.dollars << "." << money.cents << "\n";
}
Struct Padding and Binary Files
Let’s say that we wanted to save some file space when writing our PlainOldMoney structs to a binary file. We might try to decrease the size of the struct by changing the datatype of the cents member from an int (4 bytes) to a short (2 bytes).
struct PlainOldMoney {
int dollars; // int: 4 bytes
short cents; // short: 2 bytes
}
Naively we might assume the size of our struct has gone down from 8 bytes down to 6 bytes, but if we open up the associated binary file in a hex editor we’ll notice something odd: Each structure is taking up more memory than we might expect, they are still 8 bytes rather than 6!
The TL;DR is that C and C++ compilers follow certain rules which add extra padding into structs. This is because modern CPUs read and write memory most efficiently when the data is “naturally aligned”.
From a Stack Overflow thread:
“On 64 bit systems,
intshould start at addresses divisible by 4, andlongby 8,shortby 2. For struct, other than the alignment need for each individual member, the size of whole struct itself will be aligned to a size divisible by size of largest individual member, by padding at end.”
This is why our 6 byte struct was padded to 8 bytes. The largest struct member of PlainOldMoney is an int, so the overall struct size is padded such that the size becomes divisible by 4.
Read the following for more details:
- Why isn’t sizeof for a struct equal to the sum of sizeof of each member? (Stack Overflow)
- Structure Padding and Binary Files
Filesystem Library
Navigating the file system in an OS-agnostic manor is often required to:
- List files.
- Build file paths.
- Test for the existence of directory and files.
- Create directories and files.
- Copy, move, and delete directories and files.
As of C++17 we’ve had <filesystem> as part of the standard library. openFrameworks doesn’t yet support C++17 projects, so it includes a number of helper classes to work with the file system.